
Built to Be Scraped
Publishers created the open internet's information economy. AI consumed it. Now the advertising dollars are flowing somewhere to the new walled gardens

THE OBLIGATORY DISCLAIMER
Written in a personal capacity. All data comes from publicly available, verified sources. No employer input. No confidential sources. Claude assisted with research and structure. The analysis, the frustrations, and the sarcasm are entirely mine. If you find a factual error, say so in the comments and I will correct it.
On Thursday, March 26, 2026, OpenAI’s communications team sent out a press release that was, depending on your point of view, either a milestone or an indictment. The company’s advertising pilot, which had launched on February 9 with a careful announcement and explicit promises of restraint, had crossed $100 million in annualized revenue in under six weeks. More than 600 advertisers and agencies had joined the program. Target, Ford, Adobe, WPP Media, Omnicom and Dentsu were among them. Criteo had become the first formal advertising technology partner, announced on March 2. David Dugan, who had spent the previous decade helping build Meta’s advertising infrastructure into one of the most profitable machines in commercial history, had been named to lead OpenAI’s global advertising solutions team earlier that same week. Self-serve advertiser tools were scheduled for April. International expansion to Canada, Australia and New Zealand was already underway.
The reaction in the publishing industry was muted in the way that the reaction to bad news often is when the bad news has been expected for so long that the actual arrival of it produces mainly silence. The OpenAI advertising business was not a surprise. The timing and scale of it were.
Six weeks. One hundred million dollars in annualized revenue. From a standing start, reaching fewer than twenty percent of eligible users daily, with a product that places ads at the bottom of responses rather than integrated into the conversation. What that number implies about the eventual ceiling, when self-serve tools open the market in April, when international expansion adds hundreds of millions of additional users, when ad load increases from its deliberately restrained pilot level, is a question the publishing industry is now collectively trying not to think about too carefully.
To understand why the publishing industry finds this particular press release so difficult to absorb, you need to understand a chain of causation that stretches back at least three years, and possibly much longer. It begins with a simple fact: the content that powers OpenAI’s models, the reporting, the analysis, the commentary, the wikis, the forums, the reference works, the decades of archived journalism and scholarship and creative writing that gave the models the vocabulary and knowledge and context to produce fluent, accurate, useful answers, was produced by publishers. Not by OpenAI. Not by any technology company. By the journalists, editors, researchers, bloggers, academics and writers who built the open internet’s information infrastructure, piece by piece, over the past three decades.
The models consumed that infrastructure. The platforms that trained on it are now running advertising businesses. The publishers who produced it are, in many cases, fighting for survival. This article is about how that situation came to exist, what it is specifically costing the industry, what a very small number of publishers are doing about it that actually works, and what the publishing economy will look like if the structural problems are not addressed in time.
The Extraction, and How It Actually Worked
In August 2025, a document leaked that the internet’s AI economy would have preferred to keep private. Drop Site News published what appeared to be an internal Meta list of websites that the company had been systematically scraping to train its AI models. The list covered approximately six million unique websites. It included publishers of every kind: national newspapers, specialist magazines, academic journals, forums, recipe sites, legal databases, fan wikis, and personal blogs. It included content published behind robots.txt restrictions that Meta’s crawlers had bypassed. The scraping was not incidental. It was systematic, ongoing, and apparently indifferent to the commercial or legal preferences of the people who had produced what was being taken.
Meta is not an outlier here. It is, if anything, the only company for whom the documentation became public. OpenAI, Google, Anthropic, Mistral and virtually every other major AI developer built their models on the same open internet, using largely the same approach. The distinction between the companies lies in their legal strategies afterward, not in whether they scraped. Some scraped and then offered licensing deals to defuse legal risk. Some scraped and insisted it constituted fair use. Some scraped, got sued, and started negotiating. None of them asked first. The data was there. The legal framework was unclear. The commercial opportunity was enormous. The decision to wait for permission was not made.
The mechanism by which AI companies converted that scraped content into a threat to publishers operates in three stages, each of which would be damaging in isolation. Together they constitute something genuinely new in the history of platform disruption.
The first stage is training. When a large language model is trained on the text of the New York Times, the Financial Times, Reuters, Wikipedia and several hundred thousand other publications, it absorbs not just factual information but editorial judgment, contextual awareness, analytical frameworks, and writing style. The model does not merely learn facts. It learns how to think about and explain facts in ways that readers find credible and useful. That learned credibility is not the model’s. It was lent to the model by the institutions whose work formed its training data.
The second stage is inference. When a user asks ChatGPT a question, the model does not retrieve an article from a publisher’s database. It generates an answer by drawing on patterns it learned during training, patterns that were derived from publisher content. The publisher who produced the underlying reporting receives no payment for this use, no attribution in the answer, and no traffic in the form of a click. The Cloudflare data from June 2025 makes the asymmetry visible with unusual precision: Google, the search engine that at least sends some users back to publishers, generates fourteen crawls for every one referral it eventually delivers. OpenAI, which trained on publishers’ content and now answers questions based on that training, generates 1,700 crawls per single referral sent back. Anthropic, whose Claude product is built on the same content economy, generates 73,000 crawls for every referral. These numbers are not fees for content licensing. They are the ratio at which AI systems extract content versus the rate at which they return traffic value to its producers.
The third stage is advertising. This is the stage that the March 26 announcement represents. Having trained on publisher content, having built a user base of ~900 million weekly active users as of February 2026, OpenAI is now running advertisements against the audience that gravitates to its product partly because that product absorbed the knowledge and credibility of the institutions that produced the content it was trained on. The advertisers buying those ads are, in many cases, the same advertisers who used to buy from publishers. The budget that flows to OpenAI’s ad inventory is budget that does not flow to a publisher’s ad inventory. The loop is closed.
“Google is trading the public square for a walled garden built on monopoly profits. These AI-generated answers, in which Google synthesizes publisher content into Google’s own product, sit at the very top of search results. This transforms what has long been the discovery engine for our daily lives into a place where all traffic dead ends at Google.”
Jason Kint, CEO, Digital Content Next, August 2025, citing eight weeks of DCN member data
Kint’s data from the nineteen publishers in the DCN network, spanning national newsrooms and global entertainment brands, showed median Google Search referral traffic down almost every week across eight weeks in May and June 2025, with losses outpacing gains two to one. The worst single weeks were particularly stark: news publishers plunged sixteen percent in the week of May 25th. Non-news publishers fell seventeen percent in the week of June 22nd. These are not minor fluctuations or seasonal patterns. They are sustained, structural losses from content categories that Google’s AI specifically summarises at the top of the search results page.
What makes Kint’s framing more penetrating than the typical publisher complaint is that he identifies the mechanism precisely. Google is not simply building a better product that happens to reduce traffic. It is taking publisher content, using it to build an AI answer system, placing that system at the top of the search results it controls through a monopoly position that Judge Amit Mehta is currently adjudicating in the US Department of Justice antitrust case, and thereby channelling the advertising revenue that publisher traffic would have generated into Google’s own products. The content is still producing value. It is just that Google is capturing that value rather than the publisher.
What the Numbers Actually Show
The problem with how the publishing industry discusses its AI-related decline is that it frames everything as a traffic problem. Traffic is a symptom. The disease runs deeper, and it is attacking publisher revenue from multiple directions at the same time, each through a different mechanism, each at a different speed, and each compounding the others in ways that make the aggregate impact considerably worse than any individual measure suggests.
Start with the traffic. Google search traffic to publishers declined globally by thirty-three percent in the twelve months to November 2025, according to Chartbeat data covering 2,500 publisher websites. The US figure was thirty-eight percent. Google Discover, which feeds mobile users through Android and Google’s own apps and which publishers had been building supplementary strategies around, fell twenty-one percent over the same period. Pew Research Center’s study of sixty-eight thousand real user search queries, published in July 2025, found that users clicked on results eight percent of the time when AI Overviews were present, compared to fifteen percent without them. That is a forty-seven percent relative reduction in click-through rate from the same ranking position, simply because Google placed its AI summary above the publisher’s result. Advanced Web Ranking research found that AI Overviews average around 169 words and include approximately seven links when expanded. Once expanded, the first organic result often appears around 1,674 pixels down the page. The publisher is still technically present in the search results. They are just considerably less visible, considerably less likely to receive a click, and considerably less able to do anything about it.
The financial arithmetic that connects traffic decline to revenue collapse is where most external commentary misses the severity of what is happening. A twenty-five percent drop in traffic does not produce a twenty-five percent drop in programmatic revenue. It produces a forty to fifty percent drop, because publisher cost structures are largely fixed while revenue is variable. AdMonsters’s analysis from October 2025 made this precise: the infrastructure, the editorial staff, the technology stack, the licensing fees, the operational overhead, all of these continue at approximately the same level whether the site receives ten million monthly visitors or seven million. When advertising revenue falls faster than costs, the math becomes existential at a speed that quarterly earnings reports can disguise for only so long.
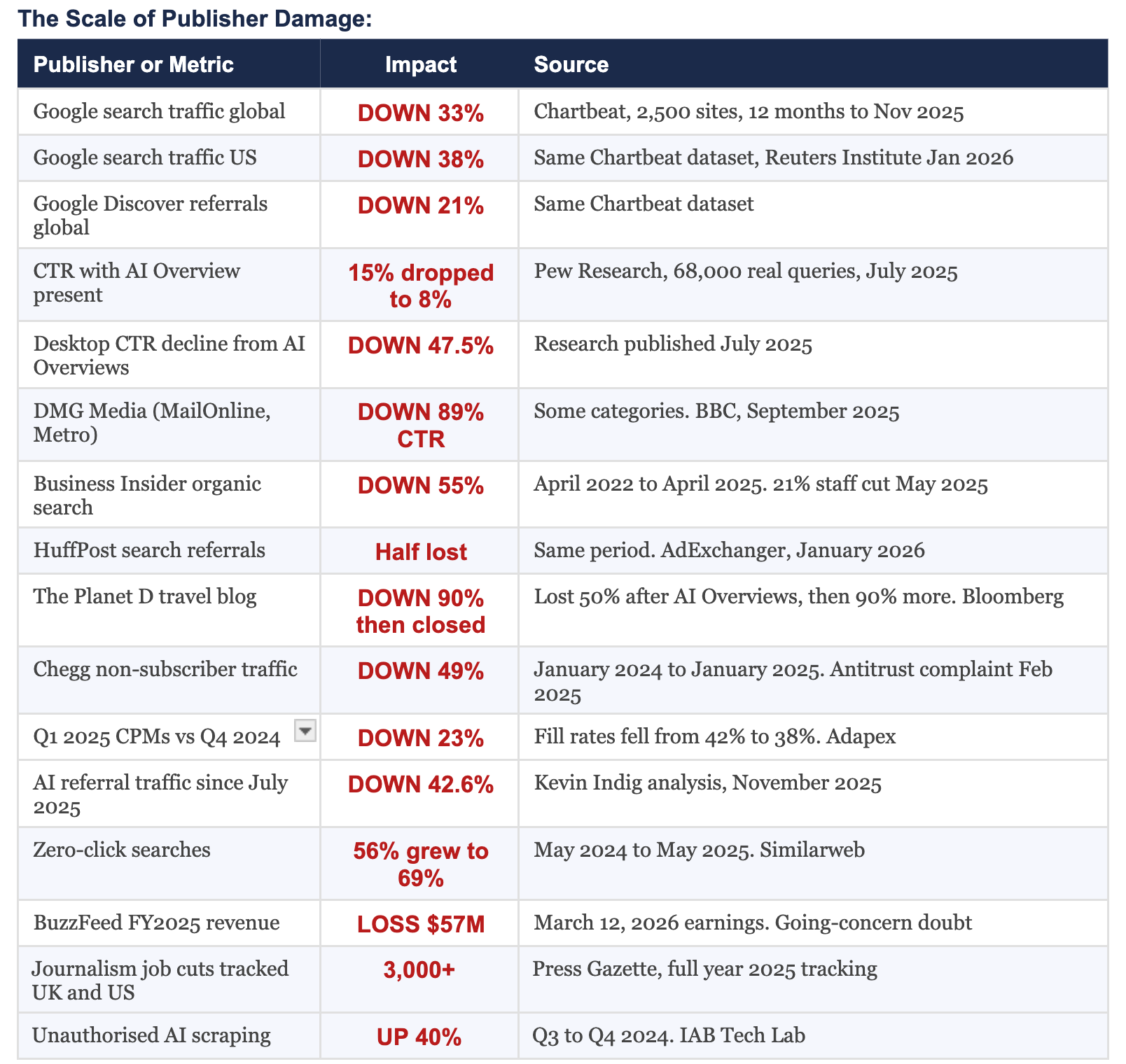
The BuzzFeed number in that table deserves a moment of separate attention. BuzzFeed, which once represented the future of digital media with sufficient conviction that it filed for a billion-dollar IPO, disclosed in its March 12, 2026 earnings release that it lost fifty-seven million dollars in revenue in 2025, that it does not currently have sufficient assets to fund its 2026 cash obligations, and that executives have substantial doubts about the company’s ability to continue operating as a going concern. This is a company that employed Pulitzer Prize-winning journalists, that genuinely pioneered the study of how content spreads on the internet, that at various points in its history was studied as a model for what a modern media company could be. It did not fail because it produced bad journalism. It failed because the business model underpinning its journalism depended on a discovery and distribution layer that has been systematically redirected by platforms that used its content to train the systems that replaced it.
BuzzFeed is the most visible casualty but not the only one. The Washington Post cut approximately one hundred staff in January 2026, with seventy-three positions in the advertising department alone. Dotdash Meredith, now renamed People Inc., cut 226 positions in October 2025 following 143 layoffs in January. HuffPost eliminated its editor-in-chief position. Travel blog The Planet D, founded in 2008, lost half its traffic when Google’s AI Overviews launched in May 2024, laid off staff in response, then lost ninety percent more traffic following those layoffs, and ceased publication entirely. Music blog Stereogum lost seventy percent of its advertising revenue in 2025, its founder Scott Lapatine attributing most of it to AI Overviews and the rest to Facebook and X deprioritising external links. Press Gazette tracked more than three thousand journalism job cuts across the UK and United States during 2025, a figure that does not include the smaller publications that closed entirely without filing public notices.
The CPM numbers in the table require equal attention, because they are the mechanism connecting traffic decline to financial distress in publishers that have not yet collapsed. Display CPMs fell thirty-three percent year-on-year in January 2025. Video CPMs fell thirty-nine percent. These are not modest corrections. They are the market pricing the fact that there are fewer verified audiences to reach, that cookie deprecation is degrading targeting precision, and that programmatic buyers increasingly prefer the authenticated, identifiable audiences in walled gardens and private marketplace deals over the anonymous, algorithmically-assembled audiences in the open programmatic exchange. A publisher who lost thirty percent of their traffic and also saw their CPMs fall thirty-three percent did not suffer a combined thirty percent revenue reduction. They suffered something approaching a fifty to sixty percent revenue reduction, before accounting for the fixed costs that did not fall with either number.
The Deals, the Lawsuits, and the Distance Between Them
Publishers have pursued two distinct strategies in response to the situation described above, and the tension between them tells you more about how the industry sees itself than any amount of conference panel discussion. Some have negotiated. Some have litigated. Most have done both, sequentially or simultaneously, with varying degrees of enthusiasm. Neither approach has solved the underlying structural problem, and both have produced outcomes whose adequacy is a matter of legitimate disagreement.
The licensing deals represent the clearest acknowledgment that publisher content has quantifiable commercial value in the AI economy. News Corp’s five-year agreement with OpenAI, reportedly worth more than $250 million according to the Wall Street Journal’s reporting from May 2024, covers the Wall Street Journal, Barron’s, MarketWatch, the New York Post, The Times and The Sunday Times of London, and a range of Australian titles. Robert Thomson, News Corp’s CEO, described it as historic and said it acknowledged that there is a premium for premium journalism. The Financial Times struck a deal worth between five and ten million dollars annually. Dotdash Meredith received at least sixteen million dollars, confirmed by IAC’s chief operating officer Chris Halpin on a Q3 2024 earnings call, who said the lion’s share of a $4.1 million year-on-year licensing revenue increase was driven by the OpenAI deal. Axel Springer agreed to a deal worth twenty-five million dollars plus variable fees. John Wiley and Sons received a one-time twenty-three million dollar payment for its academic book archive, confirmed by interim CEO Matthew Kissner on an earnings call. Curiosity Stream projected $19.6 million in AI licensing revenue from its 210,000-hour factual video library for 2025, revenue that contributed to the company’s first profitable quarter.
These deals are real money. They are also strikingly modest when measured against what the companies paying for them are spending to build the infrastructure that requires them. OpenAI committed to infrastructure partnerships with Microsoft and Amazon that total nearly three hundred billion dollars. The entire market for AI content licensing, across all publishers, all deals, all platforms, represents a fraction of a percent of what the AI companies are investing in the technology that consumes publisher content. The publishers are the essential raw material supplier for an industry that is spending hundreds of billions of dollars on the factory, and they are negotiating with considerably less leverage than that description would suggest they should have.
The Axios deal is the one that points most clearly toward what a well-structured licensing arrangement could look like. Axios signed a three-year agreement with OpenAI in 2025 under which ChatGPT answers user questions using Axios content, with clear attribution and links back to Axios’s site. What made the deal structurally different from a simple content license was that OpenAI also provided funding for Axios to open four new local newsrooms, in Pittsburgh, Kansas City, Boulder and Huntsville. The deal was not just a revenue payment for past content. It was an investment in future content production, structured around the recognition that OpenAI’s models need fresh, authoritative, locally-reported material to remain genuinely useful, and that this material requires funded journalism organizations to produce it. This is not philanthropy. It is supply chain management.
The litigants have pursued a different calculation. The New York Times filed suit against Microsoft and OpenAI in December 2023, alleging copyright infringement in the training of the models. The suit remains active. Penske Media Corporation, the owner of Rolling Stone, Variety, Deadline and The Hollywood Reporter, sued Google in September 2025, specifically arguing that AI Overviews had reduced affiliate revenue from shopping links by more than a third compared to the end of 2024, and that the summaries appear on approximately fifteen to twenty percent of search results related to PMC’s content. This suit is important because it tests a legal theory that the licensing deals cannot: that the harm occurs not in training but in inference, in the moment when Google’s AI system generates a summary that substitutes for a click that would otherwise have reached the publisher. Chegg filed an antitrust complaint in February 2025 after its non-subscriber traffic fell forty-nine percent in a single year, alleging that Google used Chegg’s educational content to train systems that now compete directly with Chegg’s core product. The argument is not just about compensation for use. It is about the use of publisher content to build a competing service.
The distance between the deals and the lawsuits is the distance between two readings of the same situation. In one reading, the AI companies are building new products that benefit users and happen to reduce publisher traffic as a side effect, and the correct response is to negotiate fair compensation for the content that enables those products. In the other reading, the AI companies are using publisher content to build products that directly substitute for what publishers provide, redistributing publisher revenue to themselves, and the correct response is to treat this as the anticompetitive conduct it arguably is. Both readings can be simultaneously true. The industry is living with that ambiguity while the revenue declines continue at a pace that is not waiting for the courts to resolve it.
The Publishers Who Are Not Dying, and the Specific Decisions That Explain Why
The publishing industry’s failures have been better documented than its successes, partly because failure is more dramatic and partly because the publishers who are navigating this period well tend not to discuss their strategies in public. There is, however, a clear and consistent pattern across the case studies that are available, and the pattern does not support the conclusion that AI disruption is uniformly destroying the industry. It supports the conclusion that publishers who built direct, authenticated relationships with their audiences are surviving, and publishers who built their economics on anonymous, algorithmically-discovered traffic are not.
The Wall Street Journal sells ninety percent of its inventory direct, against the authenticated first-party data of its paid subscriber base. Advertisers who use WSJ’s first-party data in their targeting experience a thirty-seven percent higher renewal rate than those who do not, according to a Google Ad Manager case study. That renewal rate premium is the commercial expression of something the advertising industry has always known in principle but rarely quantified: reaching the right audience in the right context produces results that justify the premium, and the publisher who can verify the audience has the leverage to price accordingly. BCG’s global digital marketing maturity survey confirms the structural advantage: first-party data delivers twice the advertising revenue per impression of non-first-party inventory. Newsweek implemented a first-party data strategy that produced average eCPM increases of fifty-two percent, with peaks reaching two hundred and twenty-four percent. These are not marginal improvements. They are the outcome of a single foundational decision: treat the subscriber relationship as a data asset, not just a revenue line.
“We are subscription first and all of our brands are paywalled properties. As a result, that’s an important part of our business. It’s also the source of our value in the advertising space because we have largely logged-in consumption. We know a great deal about the impressions and that allows us to target with precision.”
Josh Stinchcomb, Global Chief Revenue Officer, Dow Jones, Digiday+ Publisher Revenue Streams Survey, 2025
That quote, from the person responsible for revenue at the Wall Street Journal’s parent company, is the most compressed description available of what actually works. Logged-in consumption. Knowledge of the impression. Precision targeting that produces outcomes advertisers pay a premium for and renew because they can verify the outcomes. Everything in that sentence depends on one prior decision: requiring the audience to identify itself in exchange for access to the content. The publisher who has not made that decision is not merely leaving a premium on the table. They are operating without the foundational data asset that makes premium advertising possible.
Apartment Therapy Media, the parent company of the lifestyle brand Kitchn, provides a useful case study of what the transition looks like in practice. The company’s president Riva Syrop told Digiday that after traffic declines in the first half of 2025, the team spent the following three months intensively building newsletter offerings and improving its membership and retention programs. The specific goal was to increase the quantity of monetizable known visitors relative to anonymous ones. The Kitchn brand was up fifteen to twenty-five percent year-on-year every month in the period that followed. The mechanism Syrop described is worth quoting: the purpose of getting people as members is first-party data. Enabling them to have a personal experience. And then bringing that data back to the advertisers. This is not a sophisticated technological intervention. It is a commercial decision to invest in a direct audience relationship, and it is producing measurable returns in a period when publishers whose equivalent strategy is “wait for Google traffic to come back” are watching their numbers continue to deteriorate.
The WAN-IFRA sixth AI report, based on a survey of more than one hundred media leaders conducted in the second quarter of 2025, found that seventy-five percent of publishers report efficiency improvements from AI in their operations, sixty-four percent report better content production, and fifty-five percent report faster publishing times. Only nine percent can point to direct revenue gains from AI at this stage. That gap, between operational savings and commercial improvement, is the space where the decisions being made right now will determine which publishers are viable in 2028. The operational savings are real and immediate. AsiaOne in Singapore deployed an AI classification model for advertising targeting and saw revenue rise twenty percent while cutting sales staff forty percent, freeing the remaining team to focus on higher-value commercial activity. The South China Morning Post saves more than three hundred hours monthly through AI-assisted summarization, translation and editorial workflow tools. Legit.ng in Nigeria used AI to halve translation times, expanding Hausa-language coverage without proportional staff increases. Oliver Wyman’s 2025 analysis projects production cost reductions of twenty to thirty percent and labour cost savings of up to forty percent for publishers that implement AI at the operational level without using it to replace the editorial judgment that makes content worth producing.
The publishers using those savings to hire more reporters, assign more original investigations, and produce the kind of journalism that AI cannot summarize because AI cannot conduct it are the ones building the content advantage that will matter in a world where commodity content is free and distinguished content commands the premium. The publishers using those savings to produce more commodity content faster are accelerating toward a market where they will be competing against systems that produce equivalent output at literally zero marginal cost. This is a strategic decision, not a technical one, and it needs to be made consciously rather than by default.
The SSP’s Last Chance
The supply-side platform was a genuine innovation in 2008. Publishers with unsold inventory and no way to efficiently access multiple buyers simultaneously needed exactly what the SSP provided: aggregated demand, real-time auction mechanics, and the technological infrastructure to monetize remnant inventory that was otherwise worthless. That problem was real, and the companies that solved it created genuine value and were appropriately rewarded for doing so. The problem is that fifteen years later, the SSP market is largely still selling the same solution to a problem that has been transformed beyond recognition.
The Jounce Media 2025 State of the Open Internet report establishes the operational reality with unusual clarity. Publishers currently average 24.5 SSP partner relationships. Those 24.5 relationships generate bid requests of which nine out of ten go unprocessed because the system is congested with duplicate signals. Rebroadcasting, the practice of routing the same impression through multiple supply paths to generate the appearance of additional scale, accounts for thirty-seven percent of all display auctions and thirty-two percent of all video auctions. The publisher maintaining 24.5 SSP relationships is paying the operational, latency and complexity costs of those relationships in exchange for a bidstream that is mostly noise. The model that was designed to maximize demand for publisher inventory has, through proliferation and duplication, created a system where the majority of that demand is theoretical rather than real.
In August 2025, The Trade Desk made a change to its Kokai buying platform that received considerably less attention than it warranted. The company reclassified supply-side platforms from direct supply chain participants to resellers. Under Kokai’s scoring and prioritization system, SSP bid requests now receive lower priority than The Trade Desk’s own OpenPath direct connections. The implication, which Jeff Green had forecast in an earnings call months earlier, is that publishers who connect directly to The Trade Desk through OpenPath are delivering their inventory through a higher-priority path than publishers who route through even the largest SSP. Green said in that call that he expected the biggest content owners to integrate directly through OpenPath and essentially be their own SSP, particularly in connected television and audio. OpenPath’s volume grew what Green described as “many hundreds of percentage points” in 2025. OpenAds launched in January 2026 with nine publishers including the Guardian, Hearst Magazines, Newsweek and BuzzFeed, creating a transparent auction environment where publishers see bid-level data that has historically been visible only to the SSP.
The Ventura Ecosystem, announced in February 2026, integrates OpenPath, UID2 and EUID, OpenAds and OpenPass into a unified architecture that allows premium publishers to connect authenticated audience data directly to advertiser demand without SSP intermediation. OpenTTD, launched in March 2026 as a unified developer portal, is the infrastructure layer that makes this architecture accessible to publishers who want to build on it. What The Trade Desk is assembling, piece by piece and with considerable tactical patience, is a direct-to-demand infrastructure for publishers who have authenticated audiences and the commercial sophistication to operate within it.
The SSPs that are growing in this environment share a common characteristic: they have moved from being inventory aggregators to being audience intelligence platforms. PubMatic launched its AI-powered monetization platform in September 2025, integrating natural language deal setup through PubMatic Assistant, which allows publishers to configure PMP and programmatic guaranteed deals by describing them in ordinary language rather than navigating a complex interface. PubMatic Connect helps publishers package and activate their first-party audience data for buyers at the deal level. CEO Rajeev Goel’s statement at launch, that the myth of the passive publisher is over, describes the direction correctly: the SSP’s value proposition for the next decade is helping publishers communicate the specific, differentiated value of their authenticated audiences to buyers who will pay a premium for them, not aggregating anonymous inventory through an automated auction.
Magnite’s April 2025 unification of the SpringServe ad server with its programmatic SSP capabilities, deployed initially with Disney Advertising, Paramount, Roku, Samsung and Warner Bros. Discovery as clients, represents the other viable architectural direction: combining ad serving and yield management in a single system so that the publisher controls every dimension of their monetization strategy in one place. The Jounce Media March 2025 Supply Path Benchmarking Report verified that the unified platform connects buyers to ninety-nine percent of US streaming supply on a dollar-weighted basis. A publisher using this system knows what their inventory is worth, controls how it is accessed, and does not route their audience intelligence through a third party that takes a fee in exchange for providing less information than the publisher could access directly.
Onetag, the European exchange and curation platform, took a different approach when it acquired Aryel in March 2026. Aryel specializes in immersive and interactive advertising formats, including augmented reality and rich interactive experiences, that generate creative performance data alongside placement decisions. By integrating Aryel’s creative technology with Onetag’s global exchange connecting more than 2,000 publishers and 5,000 advertisers, the combined entity is building something that neither a standard SSP nor a standard creative platform can offer: a system where the quality of the creative experience, the quality of the editorial environment, and the AI-driven optimization of campaign outcomes are integrated at the infrastructure level. This matters because it addresses the question that the SSP market has never adequately answered, which is: beyond demand aggregation, what specific and measurable value does the intermediary add to the transaction? Onetag’s answer is: better outcomes, verified by creative performance data and audience quality signals, optimized in real time by AI decisioning that has access to all three elements simultaneously.
The publisher choosing SSP partners in 2026 is making a decision with long-term structural consequences. The partners who are building intelligence layers around authenticated publisher audiences, who are investing in tools that help publishers communicate audience value rather than aggregate anonymous inventory, who can demonstrate in log-level data that their participation improves yield rather than merely adding a fee to a transaction that would occur anyway, those are the relationships worth maintaining. The partners who cannot answer the question of what specific value they add to a publisher’s authenticated first-party audience inventory are the ones that The Trade Desk’s Kokai algorithm is already beginning to route around, and that AI-powered supply path optimization will route around with increasing efficiency over the next two years.
The Infrastructure Being Built Around the Problem
While the publishing industry debates its response to AI, a small number of companies has been quietly building the payment infrastructure for a world that the existing advertising economy has no mechanism to address: a world where AI systems are significant consumers of publisher content, but consume it in ways that generate no page views, no sessions, no impressions, and no advertising revenue. The problem these companies are solving is new in kind, not just in scale. The advertiser-publisher-audience triangle that has underpinned digital advertising for twenty years has a structural blind spot: it has no mechanism to capture value when the “reader” is not a human being.
TollBit, co-founded by Toshit Panigrahi and Olivia Joslin, has raised thirty-one million dollars and serves more than three thousand publisher clients. The company starts from a fact that most publishers have not fully processed: they are visited by AI crawlers at a scale that dwarfs their human readership, by systems that extract content value without generating any of the commercial signals on which advertising revenue depends. According to Cloudflare’s June 2025 data, Anthropic’s crawlers generated 73,000 crawls per single referral sent back to publishers, OpenAI’s crawlers generated 1,700 crawls per referral, and Google’s crawlers generated fourteen per referral. The publisher with a million monthly human visitors and typical crawler ratios is receiving something in the range of fifty million AI crawler visits monthly. Not one of those visits generates an impression, a session, or a commercial signal. TollBit’s bot paywall creates a payment infrastructure for exactly this category of non-human visitor, allowing publishers to set differentiated rates by purpose: the price for AI training access is different from real-time inference access, which is different from search enrichment access, because the commercial value generated by each use case is different.
TollBit’s recent addition of per-query pricing, using Microsoft’s NLWeb protocol, addresses a point that IAB Tech Lab CEO Anthony Katsur made explicitly: one crawl can feed ten thousand queries, fifty thousand queries, and the publisher has been paid only once for the crawl. Per-query pricing converts the relationship between a publisher’s content and an AI system’s output from a one-time transaction to an ongoing royalty structure. It is, in commercial principle, the same model that music rights holders use when they licence recordings for streaming: not a one-time payment for a file, but a per-play fee that accumulates over time relative to actual usage.
ProRata took a different route to the same destination. The company, which raised forty million dollars in Series B funding in September 2025 and has more than five hundred publisher partners, built Gist.ai, an AI search engine that uses only licensed publisher content and distributes fifty percent of all revenue generated by that search engine to publishers based on how often their content powers the responses. The Atlantic, Time, Fortune, ADWEEK, BuzzFeed and Lee Enterprises are among the participants. The model’s structural advantage over Cloudflare’s and TollBit’s bot-paywall approaches is that it does not require AI companies to opt into payment before the model generates revenue. ProRata creates a separate commercial ecosystem where licensed content is the only content, advertising runs against the answers that licensed content powers, and revenue flows monthly to the publishers whose content was cited. It is a parallel economy rather than a reformed version of the existing one.
Cloudflare’s Pay Per Crawl marketplace, launched on July 1, 2025, operates at a different scale than either TollBit or ProRata because Cloudflare sits in front of approximately sixteen percent of all global internet traffic. The company blocks AI crawlers by default for new websites and has created a market where publishers can set micropayment rates per page access. The publisher participants at launch read like a partial inventory of what the open web’s premium content looks like: Conde Nast, Dotdash Meredith, the Associated Press, The Atlantic, TIME, Fortune, BuzzFeed, Gannett, Reddit and Universal Music Group. Conde Nast CEO Roger Lynch: when AI companies can no longer take anything they want for free, it opens the door to sustainable innovation built on permission and partnership. Neil Vogel, CEO of Dotdash Meredith: we can now limit access to our content to those AI partners willing to engage in fair arrangements. These statements describe a commercial reality that is only beginning to materialize. The Cloudflare marketplace does not yet represent the majority of publisher-to-AI company transactions. It represents the architecture for what those transactions could become once the legal and commercial frameworks catch up with the technical infrastructure.
Microsoft’s pay-per-use AI content marketplace, which signed both the Associated Press and USA Today in 2025, is the first attempt by a major AI company itself to build systematic market infrastructure rather than negotiating individual bilateral deals. The significance of this is not merely commercial. It is a signal that at least one major AI platform has concluded that the sustainable model for content access involves a functioning market rather than a series of separately negotiated agreements at different prices, with different terms, signed by publishers who have no way to benchmark what anyone else received. A market is better for publishers than bilateral negotiations, because a market creates pricing transparency and allows any publisher to understand the fair value of their content relative to comparable titles. Markets are generally better for buyers too, because markets are more efficient than individual negotiations. The fact that Microsoft is building one suggests that the current state of bilateral dealing is recognized as unsatisfactory even by the companies that have benefited from it.
The Dependency Nobody Wants to Discuss
There is a structural dependency embedded in the AI economy that the AI companies prefer not to emphasize and the publishing industry has been slow to recognize as leverage. The large language models that power every major AI product on the market were trained on human-produced content. Not on synthetic data. Not on AI-generated text. On the journalism, analysis, fiction, scholarship, instruction, commentary and conversation that human beings produced and published over several decades. The models learned to write well because they read writing that was good. They learned to reason about complex topics because they absorbed reasoning about complex topics. They learned which facts are reliable because they trained on sources with editorial standards and accountability structures. When the training data degrades, which it will if the institutions producing it can no longer afford to operate, so do the models.
This dependency is already visible in the way AI companies are competing for content. News Corp’s $250 million deal with OpenAI was not the price of a favour. It was the market rate for an archive that provides exactly the kind of verified, sourced, dated, contextually-rich content that makes models more accurate and trustworthy. Google’s first AI content deal, struck with the Associated Press in 2025, gives Gemini access to AP’s real-time news production. Washington Post joined OpenAI in April 2025. The New York Times struck a deal with Amazon for Alexa and Amazon’s AI products. These companies are not paying for content because Sam Altman woke up one morning with a conscience about journalism. They are paying because the models need it and the alternative is litigation that could set precedents substantially more expensive than the licensing fees.
Axios understood this dependency more clearly than most when it negotiated not just payment but investment: OpenAI funding four new local newsrooms in exchange for content access is a recognition that the model’s value depends on the continued production of authoritative local reporting, and that this reporting requires funded organizations to produce it. The deal creates a direct commercial incentive for OpenAI to ensure that Axios has the resources to keep generating the content the model needs. This is a structural arrangement, not a charitable gesture, and it is the model that the rest of the licensing market should be working toward.
The publishers who have recognized this dependency as leverage are the ones building the most durable commercial positions. The Financial Times’s Storyfinding team uses AI to surface patterns in large datasets, which human reporters then investigate. The model’s ability to spot patterns in financial data only creates value if a reporter with decades of markets expertise can assess which patterns are significant and pursue the story. That reporting is what makes the FT worth licensing, worth subscribing to, and worth citing in AI answers. The AI improves the reporter’s efficiency. The reporter validates and extends what the AI found. The content that results is both more efficiently produced and more exclusively valuable than it would have been without either component. This is the correct division of labour, and it produces content that AI platforms will continue to need and pay for precisely because it cannot be replicated without the human component.
The publisher who has not made this calculation is still producing content in the old way, at the old cost, for an audience that the AI has redirected. The window in which they can use the operational savings that AI tools make possible to reinvest in the irreplaceable reporting that makes their content worth licensing is not infinite. The models are already training on a substantial volume of AI-generated text, and research suggests this degrades model quality over successive generations of training. The premium that authentic, human-reported, editorially-verified content commands in the AI training market will increase as synthetic content proliferates and the scarcity of genuine human expertise becomes more visible. The publishers who are still producing it in 2028 will be in a stronger negotiating position than those who have already cut the editorial functions that make their content distinctive.
The argument that publishers have genuine leverage in this situation is not naive optimism. It is grounded in the specific dependency the AI companies cannot route around. They need original, verified, recently-produced, contextually-rich human content to remain credible and useful. Without it, the models degrade, hallucinate more frequently, and lose the currency that makes them commercially valuable. Every major AI company knows this, which is why they are paying for licensing deals, funding newsrooms, and building compensation infrastructure rather than simply continuing to scrape freely and defend the practice in court. The leverage exists. The question is whether publishers are willing to price it like the asset it is, rather than continuing to treat access to their content as a default that any technology company is entitled to use.
What Needs to Happen, in Order
The publishing industry is at the point in a structural disruption where the companies that adapt early enough to rebuild their foundations before the revenue collapse reaches critical mass will survive, and those that delay will not. This is not a new observation about disrupted industries. It is, however, an observation with a specific urgency in this case because the pace of the structural change, as measured by the traffic and CPM numbers, is faster than the timeline on which most publishing companies make strategic decisions.
The first decision is architectural and cannot be deferred: publishers need to know who their audience is. Not the monthly uniques number in the analytics dashboard, which measures anonymous visits that have no commercial value in the world being built around them. The number of verified email addresses from people who have actively provided them. The count of logged-in sessions in the past thirty days. The active subscriber total. A publisher who cannot answer these questions with precision does not have an audience in the commercially meaningful sense. They have traffic, and traffic is what they are losing.
The second decision is about content investment. AI tools make it genuinely possible to produce the operational work of a newsroom, the formatting, the metadata, the headline testing, the distribution scheduling, the translation, the summarization, at significantly lower cost than before. The question every editorial leadership team needs to answer is whether those savings are being reinvested in the work that AI cannot do: the investigations that require a reporter in the room, the analysis that requires expertise built over years, the accountability journalism that requires the institutional weight to withstand legal and political pressure. If the answer is no, then the publication is using AI to accelerate its own commoditization.
The third decision is about the supply chain. A publisher running 24.5 SSP relationships while nine in ten bid requests go unprocessed is not operating a monetization strategy. They are operating the simulation of one, at the cost of latency, complexity and the fee that each intermediary extracts from each transaction that does complete. The publishers ahead of this curve are consolidating their SSP relationships to partners who can demonstrate, in log-level data and verifiable yield analysis, that their participation adds margin to the publisher’s inventory rather than extracting it. They are exploring direct connections through OpenPath and OpenAds for their premium authenticated inventory, where the buyer’s demand can reach the publisher’s audience without an intermediary taking a percentage of a transaction that the intermediary did not originate.
The fourth decision is about AI access pricing. Publishers who have not established a commercial position with AI crawlers, through Cloudflare’s marketplace, TollBit’s bot paywall, ProRata’s licensing pool, or bilateral negotiations with AI companies, have implicitly priced their content at zero for AI access. Zero is not a business decision. It is the absence of one. The price of content in the AI training market is in the process of being established right now, through the deals being signed and the court cases being argued. Publishers who participate in establishing that market price, even at modest initial levels, are building commercial relationships and legal frameworks that will matter considerably more once the regulatory environment catches up with the commercial one.
The fifth decision is one of framing, and it is the one the industry finds hardest to make: publishers need to stop thinking of their problem as a traffic problem and start thinking of it as an asset pricing problem. The content is an asset. The authenticated subscriber relationship is a more valuable asset. The editorial authority that makes a publication worth citing in an AI answer is an asset. The twenty-year archive of verified, dated, sourced, human-produced reporting is an asset that AI companies have demonstrated they will pay for when the alternative is litigation. None of these assets is worth its full potential value if the publisher has not built the commercial infrastructure to price and sell them. Building that infrastructure is the work of the next eighteen months, and for the publishers who do not start it, the next eighteen months may be the last period in which starting is an option.
The content that made the open internet’s information economy possible was produced by people who took professional and financial risks to report things that were difficult to report, to explain things that were difficult to explain, to hold accountable people and institutions that would have preferred not to be held accountable. The AI companies consumed that content to build products that are now generating hundreds of billions of dollars in enterprise value. The deal they are currently offering to publishers, modest per-article licensing fees and the promise of citation-with-attribution, is the deal that the only party with leverage in the negotiation should be able to improve. The leverage is real. The dependency is structural. The window is closing, but it has not closed yet.